
Introducing ABENA: BERT Natural Language Processing for Twi
Introduction
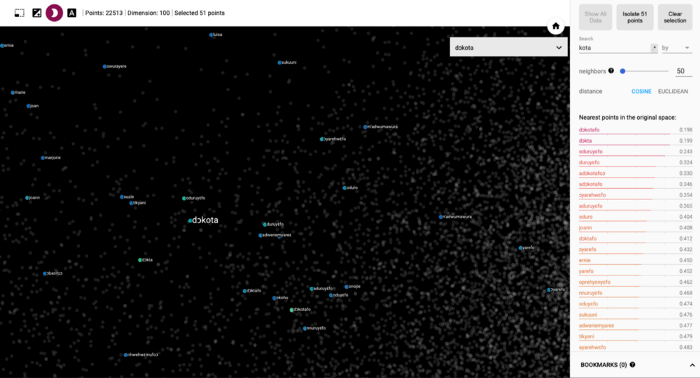
In our previous blog post we introduced a preliminary Twi embedding model based on fastText and visualized it using the Tensorflow Embedding Projector. As a reminder, text embeddings allow you to convert text into numbers or vectors which a computer can perform arithmetic operations on to enable it reason about human language, i.e., carry out natural language processing (NLP). A screenshot of our fastText Twi embeddings from that exercise is shown in Fig. 2.

This model— which we have shared in our Kasa Library repo — enables a computer to begin to reason in Twi computationally. However it is “static” in the sense that the vectors do not change with different contexts. State-of-the-art NLP in high-resource languages such as English has largely moved away from these to more sophisticated “dynamic” embeddings capable of understanding a changing contexts. The most prominent example of such a dynamic embedding architecture is BERT — Bidirectional Encoder Representations from Transformers.
In this post, we introduce ABENA —A BERT model Now in Akan. We introduce at least four different flavors of ABENA:
- We first employ transfer learning to fine-tune a multilingual BERT (mBERT) model on the Twi subset of the JW300 dataset, which is the same data we used to develop our fastText model. This data is largely composed of the Akuapem dialect of Twi (clean data copy available from links in this paper).
- Subsequently, we fine-tune this model further on the Asante Twi Bible data to obtain an Asante Twi version of the model.
- Additionally, we perform both experiments using the DistilBERT architecture instead of BERT — this yields smaller and more lightweight versions of the (i) Akuapem and (ii) Asante ABENA models.
Additionally, we introduce BAKO — BERT with Akan Knowledge Only. This is essentially the same as ABENA, but the entire model is trained from scratch. Due to the low-resource nature of Twi and the large size of BERT, we only share a lighter and smaller RoBERTa version of BAKO (which is even smaller than DistilBERT). RoBERTa stands for Robustly Optimized BERT Approach and employs clever optimization tricks to improve on BERT efficiency.
We share all models through the Hugging Face Model Hub allowing you to begin executing modern NLP on your Twi data in just a few lines of Python code. Concepts are linked to Kaggle notebooks illustrating them whenever possible, to enable you to test out the ideas in code very quickly. To use ABENA to fill in the blanks in the blanks, for instance, it is sufficient to execute the following python code.
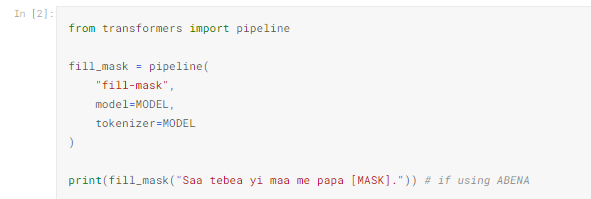
Here, MODEL is just a string name of one of our available models, such as the following.

In this example, we are looking for a plausible completion for the Twi sentence “Saa tebea yi maa me papa ____”. The top completion returned by this model is “Saa tebea yi maa me papa paa”, which is very plausible. It turns out that this seemingly simple ability to fill-in-the-blanks can be key to a variety of tasks, such as text classification, text generation, language representation, spell-checking, etc.
This work represents yet another step we are taking at NLP Ghana to modernize the state of computational methods for Ghanaian languages. You can find code for replicating all of these results and training your own models on GitHub.
Motivation
Transformer-based language models have been changing the modern NLP landscape for high-resource languages such as English, Chinese, Russian, etc. However, this technology does not yet exist for any Ghanaian languages. In this post, we introduce the first such model for Twi/Akan, arguably the most widely spoken Ghanaian language.
Unlike the static embeddings like word2vec and fastText, transformer-based language models have the ability to dynamically adapt to changing contexts. For instance, consider the following two English sentences:
- He examined the cell under the microscope.
- He was locked in a cell.
The same word cell here means two completely different things. A human would look at the context, i.e., the words surrounding our target word, for cues about the exact meaning. The word microscope clearly brings up biological connotations in the first sentence. The word locked clearly brings up connotations of a prison in the second sentence.
To make a Twi example, consider the following two sentences.
- ɔkraman no so paa — the dog is very big
- ɔkra no da mpa no so — the cat is sleeping on the bed
The word “so” means “big” in the first sentence and “on” in the second sentence.
Transformer-based models possess the ability to dynamically analyze the context for meaning cues, and adapt to it. They do this using the so called self-attention mechanism, which we do not discuss in detail here. BERT is arguably the most popular model from this class. It is typically trained with a “fill-in-the-blanks” objective which is very practical to implement and does not require labeled data — just randomly drop some words and try to predict them.
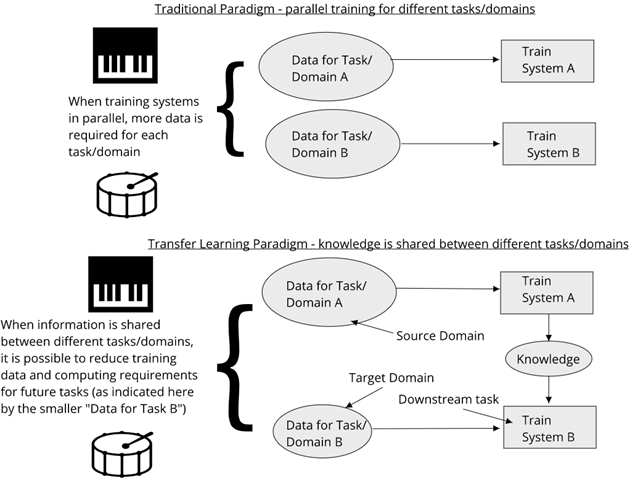
These models are equipped with the ability to be adapted or fine-tuned to new tasks, scenarios and languages. This adaptation process is also referred to as transfer learning, and was used in computer vision for a while before it became popular in NLP. Nowadays, it is a lot less common to train any model from scratch — instead, models trained to fill-in-the blanks (and other tasks) on billions of words are shared openly and fine-tuned to new scenarios using very little additional data. This is more representative of how humans learn, as we typically make associations to what we already know when faced with new challenges. The idea of Transfer Learning is illustrated in Fig. 3.
Since BERT is a very large model, being approximately 179 million parameters in size, a number of recent efforts have been aimed at making them smaller and more lightweight. These include ALBERT, TinyBERT, RoBERTa and DistilBERT. Here, we employ DistilBERT, which employs a technique known as knowledge distillation, to produce smaller distilled versions of ABENA. We also experiment with RoBERTa for training models from scratch.
ABENA Twi BERT Models
The first thing we do is initialize a BERT architecture and tokenizer to the multilingual BERT (mBERT) checkpoint. This model was trained on over 100 languages simultaneously. Although these did not include any Ghanaian languages, it does include another “Niger-Congo” language — Nigerian Yoruba. It is thus reasonable to expect that this model contains some knowledge useful for constructing a Twi embedding. We transfer this knowledge by fine-tuning the initialized mBERT weights and tokenizer on the monolingual Twi. The convergence info is shown in Fig 4. All models were trained on a single Tesla K80 GPU on an NC6 Azure VM instance.

Note that the time to run 3 epochs is significantly shorter for the Asante model because the Asante Twi Bible is significantly smaller than JW300 (25k+ samples versus 600k+ samples). Moreover, note that we further made the Asante model uncased due to this smaller training data size. This just means that the model doesn’t distinguish between upper and lower cases of letters, while the Akuapem model does. We present the final loss value attained for all models, in the absence of any other benchmarks available for the Twi languages. In the final section we will outline some of the things we are doing to address this lack of benchmarks.
Next, we perform the same experiments using the DistilBERT architecture instead of BERT, to yield smaller and more lightweight versions of both the Akuapem and Asante ABENA models. DistilBERT employs a technique known as knowledge distillation to reduce the size of the model while sacrificing little of the performance. If DistilBERT is the distilled version of BERT, then DistilABENA is the distilled version of ABENA. The distilled models have approximately 135 million parameters, which is 75% of the 179 million parameters in the BERT-based models.
Moreover, we experiment with training our own tokenizer on the monolingual Twi data prior to fine-tuning from pretrained multilingual weights — versus using the included pretrained multilingual tokenizer to do the same. This yields “V2” versions of the distilled models, with significantly higher final loss values as shown in Fig. 4. We deploy and share these models as well, to make it easy for the community to further experiment with and fine-tune them. Intuitively, we expect a monolingual tokenizer to eventually be more precise, even if the quality and amount of the training data at the moment precludes us from demonstrating this.

BAKO Twi BERT Model
Finally, we investigated training the various forms of ABENA described in the previous section from scratch on the monolingual data. We named these set of models BAKO — “BERT with Akan Knowledge Only. An apt visualization of what the Ghanaian character BAKO probably looks like is shown in Fig. 6.

We found BERT and DistilBERT not suitable for this right now, given the relatively small size of the dataset (JW300). For this reason we only presented the RoBERTa versions of BAKO, i.e., RoBAKO — Robustly Optimized BAKO. RoBERTa is an improvement on BERT that employs clever optimization tricks for better efficiency. In particular, among other improvements, we use byte-pair encoding (BPE) for tokenization, which is arguably more effective than the WordPiece approach used by BERT and DistilBERT. In fact, the RoBERTa-based models have “only” 84 million parameters, which is just 47% the size of the BERT-based models. We show our training information for these models in Fig 7.

Interestingly, we found the loss values to be almost exactly equal to the “V2” DistilABENA models from the previous section (compare with Fig. 5).
Simple Sentiment Analysis/Classification Example
By way of summary, in Fig. 8 we list and describe all the models we have presented. You can also find them listed on the Hugging Face Model Hub.

Alright then, how do we actually use these to do useful practical stuff? We have curated some useful demos of these models in the following Kaggle Notebook. All you have to do is hit “Copy & Edit” at the top right corner (after creating a Kaggle account) to begin to use our models. Kaggle will also give you 30–40 hours of free GPU compute per week, which you can use to further fine-tune the models to your own scenarios, datasets and applications.
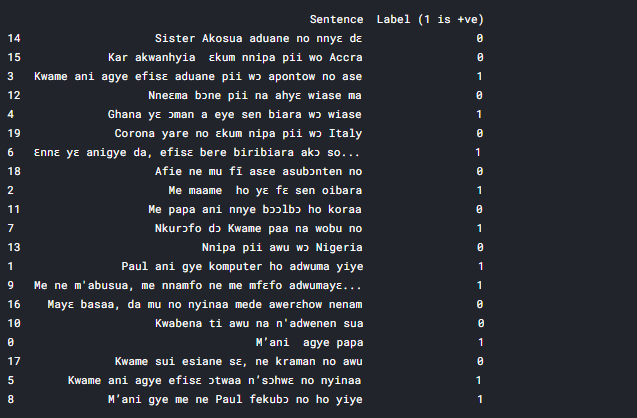
In the notebook, we show how to extract embedding vectors for words and sentences, as well as how to fill-in-the-blanks. Moreover, we created a simple Sentiment analysis dataset of just 10 positive and 10 negative example sentences, to see if we could build a classifier by training on 14 of the 20 samples and testing on the remaining 6. This dataset we quickly wrote up is shown in Fig. 9.
We were pleasantly surprized to find that, as long as care is taken to select a reasonably balanced training sample, the prediction accuracy varied anywhere between 70% to 100% (!) from run to run. This is despite using a simple k-nearest-neighbor classifier from sklearn, which is a similarity based method, and these BERT models are yet to be fine-tuned to perform well on a similarity task! Just imagine what we could do with some reasonably sized training datasets!
Limitations and Ongoing/Future Work
The models show a varying degree of religious bias. For instance when completing a sentence like “Eyi de ɔhaw kɛse baa ____ hɔ”, you may see completions such as “Eyi de ɔhaw kɛse baa Adam hɔ” and/or “Eyi de ɔhaw kɛse baa Satan hɔ” among the most likely completions. While these are not technically wrong, and can be useful for understanding sentence structure, named entity recognition, etc., the fact that these are among the top 5 completions indicate a strong religious bias in the model. This is obviously due to the religious data used to train them.
This is the best we could do at the moment, due to the extreme low resource nature of Twi, and it is clearly already a useful set of models. However, it is very important to communicate that this is a work in progress, and the models should be used with care and awareness of their religious bias.
The work presented opens up a number of research directions for us to pursue in order to further improve these models, bring them up to a “state-of-the-art” global standard level, and enable many critical applications. In no particular order, the following list describes these research efforts, some of which are already ongoing at NLP Ghana.
- Fine-tuning on cleaner/higher quality/less-biased unlabeled data (cleaner datasets in development)
- Developing a Twi version of the labeled GLUE Dataset for fine-tuning on many other tasks, such as entailment, sentiment analysis, sentence similarity, etc.
- Training ALBERT for Twi and comparing with presented models. This architecture promises an even greater size saving than RoBERTa.
- Unsupervised spell checking methods based on these models
- Unsupervised Named Entity Recognition (NER) methods based on these models
- Developing a Twi version of the GPT-2 (and GPT-3?) causal Transfomer-based text generator
- Developing a large labeled Named Entity Recognition (NER) dataset, e.g., a translation of CONLL 2003, and fine-tuning these models on them
- Incorporating all of the above developments into the our one-stop Open Kasa Library to make all of these Ghanaian NLP tools readily available to NLP developers and practitioners
- Doing all of the above for any and all of the other Ghanaian languages!
Related post